准备深入学习Netty,所以抽空复习下NIO
在原译文基础上修改了部分错别字,以及修正了有误的代码示例
Java NIO 概述
Java NIO 由以下几个核心部分组成
- Channels
- Buffers
- Selectors
Channel 和 Buffer
基本上,所有的 IO 在NIO 中都从一个Channel 开始。Channel 有点象流。 数据可以从Channel读到Buffer中,也可以从Buffer 写到Channel中。
主要Channel的实现
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
关键的Buffer实现
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
Selector
Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中。
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
Channel
FileChannel 从文件中读写数据。
DatagramChannel 能通过UDP读写网络中的数据。
SocketChannel 能通过TCP读写网络中的数据。
ServerSocketChannel 可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
基本的 Channel 示例
使用FileChannel读取数据到Buffer中,注意 buf.flip() 的调用,首先读取数据到Buffer,然后反转Buffer,接着再从Buffer中读取数据。
RandomAccessFile aFile = new RandomAccessFile("nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(48);
// 写入数据到Buffer
int bytesRead = inChannel.read(buf);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
// flip
buf.flip(); // make buffer ready for read
// 从Buffer中读取数据
while(buf.hasRemaining())
System.out.print((char) buf.get()); // read 1 byte at a time
// 调用clear()方法或者compact()方法
buf.clear(); // make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();
Buffer
Java NIO中的Buffer用于和NIO通道进行交互。数据是从通道读入缓冲区,从缓冲区写入到通道中的。
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
Buffer的基本用法
使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
Buffer的capacity, position 和 limit
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
为了理解Buffer的工作原理,需要熟悉它的三个属性:
- capacity
- position
- limit
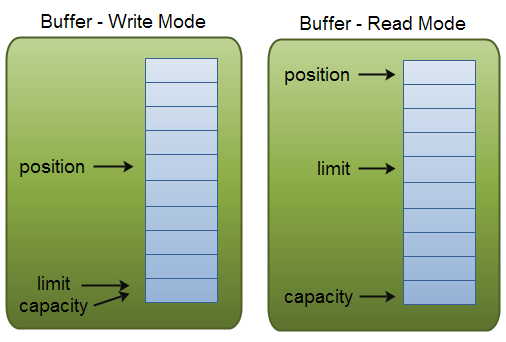
capacity
作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”.你只能往里写capacity个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
position
当你写数据到Buffer中时,position表示当前的位置。初始的position值为0.当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1.
当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
limit
在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。
当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
public final boolean hasRemaining() {
return position < limit;
}
public byte get() {
return hb[ix(nextGetIndex())];
}
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
protected int ix(int i) {
return i + offset;
}
Buffer的类型
Java NIO 有以下Buffer类型
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
这些Buffer类型代表了不同的数据类型。换句话说,就是可以通过char,short,int,long,float 或 double类型来操作缓冲区中的字节。
MappedByteBuffer 有些特别,在涉及它的专门章节中再讲。
Buffer的分配
要想获得一个Buffer对象首先要进行分配。 每一个Buffer类都有一个allocate方法。
下面是一个分配48字节capacity的ByteBuffer的例子。
ByteBuffer buf = ByteBuffer.allocate(48);
这是分配一个可存储1024个字符的CharBuffer:
CharBuffer buf = CharBuffer.allocate(1024);
向Buffer中写数据
写数据到Buffer有两种方式
- 从Channel写到Buffer
- 通过Buffer的put()方法写到Buffer里
从Channel写到Buffer的例子
int bytesRead = inChannel.read(buf); // read into buffer.
通过put方法写Buffer的例子
buf.put(127);
put方法有很多版本,允许你以不同的方式把数据写入到Buffer中。例如, 写到一个指定的位置,或者把一个字节数组写入到Buffer。 更多Buffer实现的细节参考JavaDoc。
flip()方法
flip方法将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值。
换句话说,position现在用于标记读的位置,limit表示之前写进了多少个byte、char等 —— 现在能读取多少个byte、char等。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
从Buffer中读取数据
从Buffer中读取数据有两种方式:
- 从Buffer读取数据到Channel
- 使用get()方法从Buffer中读取数据
从Buffer读取数据到Channel的例子
int bytesWritten = inChannel.write(buf);
使用get()方法从Buffer中读取数据的例子
byte aByte = buf.get();
get方法有很多版本,允许你以不同的方式从Buffer中读取数据。例如,从指定position读取,或者从Buffer中读取数据到字节数组。更多Buffer实现的细节参考JavaDoc。
rewind()方法
Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据。limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)。
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
clear()与compact()方法
一旦读完Buffer中的数据,需要让Buffer准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设回0,limit被设置成 capacity的值。换句话说,Buffer 被清空了。Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。
如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。
compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
public final int remaining() {
return limit - position;
}
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
public final int capacity() {
return capacity;
}
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
final void discardMark() {
mark = -1;
}
mark()与reset()方法
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。
public final Buffer mark() {
mark = position;
return this;
}
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
equals()与compareTo()方法
可以使用equals()和compareTo()方法两个Buffer。
equals()
当满足下列条件时,表示两个Buffer相等
- 有相同的类型(byte、char、int等)
- Buffer中剩余的byte、char等的个数相等
- Buffer中所有剩余的byte、char等都相同
equals只是比较Buffer的一部分,不是每一个在它里面的元素都比较。实际上,它只比较Buffer中的剩余元素(从 position到limit之间的元素)。
public boolean equals(Object ob) {
if (this == ob)
return true;
if (!(ob instanceof ByteBuffer))
return false;
ByteBuffer that = (ByteBuffer)ob;
if (this.remaining() != that.remaining())
return false;
int p = this.position();
for (int i = this.limit() - 1, j = that.limit() - 1; i >= p; i--, j--)
if (!equals(this.get(i), that.get(j)))
return false;
return true;
}
compareTo()
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer
- 第一个不相等的元素小于另一个Buffer中对应的元素
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)
public int compareTo(ByteBuffer that) {
int n = this.position() + Math.min(this.remaining(), that.remaining());
for (int i = this.position(), j = that.position(); i < n; i++, j++) {
int cmp = compare(this.get(i), that.get(j));
if (cmp != 0)
return cmp;
}
return this.remaining() - that.remaining();
}
Scatter/Gather
Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(Channel在中文经常翻译为通道)中读取或者写入到Channel的操作。
分散(scatter)从Channel中读取是指在读操作时将读取的数据写入多个buffer中。因此,Channel将从Channel中读取的数据“分散(scatter)”到多个Buffer中。
聚集(gather)写入Channel是指在写操作时将多个buffer的数据写入同一个Channel,因此,Channel 将多个Buffer中的数据“聚集(gather)”后发送到Channel。
scatter / gather经常用于需要将传输的数据分开处理的场合,例如传输一个由消息头和消息体组成的消息,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
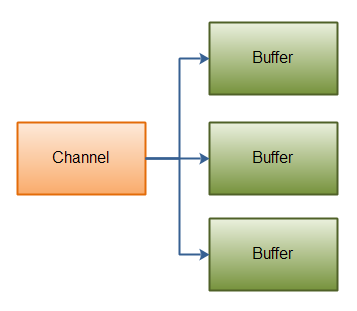
Scattering Reads
Scattering Reads是指数据从一个channel读取到多个buffer中。
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.read(bufferArray);
注意buffer首先被插入到数组,然后再将数组作为channel.read() 的输入参数。read()方法按照buffer在数组中的顺序将从channel中读取的数据写入到buffer,当一个buffer被写满后,channel紧接着向另一个buffer中写。
Scattering Reads在移动下一个buffer前,必须填满当前的buffer,这也意味着它不适用于动态消息(消息大小不固定)。换句话说,如果存在消息头和消息体,消息头必须完成填充(例如 128byte),Scattering Reads才能正常工作。
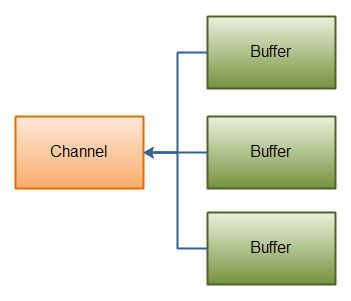
Gathering Writes
Gathering Writes是指数据从多个buffer写入到同一个channel。
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
buffers数组是write()方法的入参,write()方法会按照buffer在数组中的顺序,将数据写入到channel,注意只有position和limit之间的数据才会被写入。因此,如果一个buffer的容量为128byte,但是仅仅包含58byte的数据,那么这58byte的数据将被写入到channel中。因此与Scattering Reads相反,Gathering Writes能较好的处理动态消息。
通道之间的数据传输
在Java NIO中,如果两个通道中有一个是FileChannel,那你可以直接将数据从一个channel传输到另外一个channel。
transferFrom()
FileChannel的transferFrom()方法可以将数据从源通道传输到FileChannel中(译者注:这个方法在JDK文档中的解释为将字节从给定的可读取字节通道传输到此通道的文件中)。
RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
FileChannel fromChannel = fromFile.getChannel();
RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
FileChannel toChannel = toFile.getChannel();
long position = 0;
long count = fromChannel.size();
toChannel.transferFrom(fromChannel, position, count);
方法的输入参数position表示从position处开始向目标文件写入数据,count表示最多传输的字节数。如果源通道的空间小于 count 个字节,则所传输的字节数要小于请求的字节数。
此外要注意,在SoketChannel的实现中,SocketChannel只会传输此刻准备好的数据(可能不足count字节)。因此,SocketChannel可能不会将请求的所有数据(count个字节)全部传输到FileChannel中。
transferTo()
transferTo()方法将数据从FileChannel传输到其他的channel中
RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
FileChannel fromChannel = fromFile.getChannel();
RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
FileChannel toChannel = toFile.getChannel();
long position = 0;
long count = fromChannel.size();
fromChannel.transferTo(position, count, toChannel);
上面所说的关于SocketChannel的问题在transferTo()方法中同样存在。SocketChannel会一直传输数据直到目标buffer被填满。
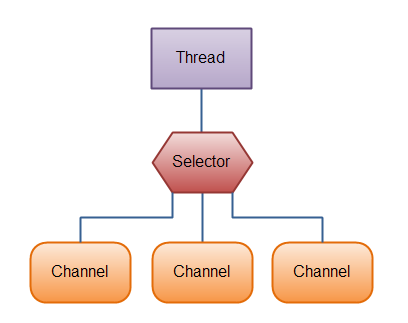
Selector
Selector(选择器)是Java NIO中能够检测一到多个NIO通道,并能够知晓通道是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。
为什么使用Selector?
仅用单个线程来处理多个Channels的好处是,只需要更少的线程来处理通道。事实上,可以只用一个线程处理所有的通道。对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源(如内存)。因此,使用的线程越少越好。
但是,需要记住,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。实际上,如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。不管怎么说,关于那种设计的讨论应该放在另一篇不同的文章中。在这里,只要知道使用Selector能够处理多个通道就足够了。
Selector的创建
通过调用Selector.open()方法创建一个Selector
Selector selector = Selector.open();
向Selector注册通道
为了将Channel和Selector配合使用,必须将channel注册到selector上。通过SelectableChannel.register()方法来实现。
SocketChannel channel = SocketChannel.open();
Selector selector = Selector.open();
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
与Selector一起使用时,Channel必须处于非阻塞模式下。这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式。而套接字通道都可以。
注意register()方法的第二个参数。这是一个“interest集合”,意思是在通过Selector监听Channel时对什么事件感兴趣。可以监听四种不同类型的事件:
- Connect
- Accept
- Read
- Write
通道触发了一个事件意思是该事件已经就绪。所以,某个channel成功连接到另一个服务器称为“连接就绪”。一个server socket channel准备好接收新进入的连接称为“接收就绪”。一个有数据可读的通道可以说是“读就绪”。等待写数据的通道可以说是“写就绪”。
这四种事件用SelectionKey的四个常量来表示:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
如果你对不止一种事件感兴趣,那么可以用“位或”操作符将常量连接起来。
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
在下面还会继续提到interest集合。
SelectionKey
当向Selector注册Channel时,register()方法会返回一个SelectionKey对象。
- interest集合
- ready集合
- Channel
- Selector
- 附加的对象(可选)
interest集合
通过SelectionKey读写interest集合。
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
int interestSet = key.interestOps();
boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
interestSet & ~x 将x删除
interestSet | x 将x添加进去
用“位与”操作interest 集合和给定的SelectionKey常量,可以确定某个确定的事件是否在interest 集合中。
ready集合
ready 集合是通道已经准备就绪的操作的集合。在一次选择(Selection)之后,你会首先访问这个ready set。Selection将在下一小节进行解释。
int readySet = key.readyOps();
可以用像检测interest集合那样的方法,来检测channel中什么事件或操作已经就绪。但是,也可以使用以下四个方法,它们都会返回一个布尔类型。
key.isAcceptable();
key.isConnectable();
key.isReadable();
key.isWritable();
Channel + Selector
从SelectionKey访问Channel和Selector很简单。
Channel channel = key.channel();
Selector selector = key.selector();
附加的对象
可以将一个对象或者更多信息附着到SelectionKey上,这样就能方便的识别某个给定的通道。例如,可以附加 与通道一起使用的Buffer,或是包含聚集数据的某个对象。
key.attach("str");
Object attachment = key.attachment();
还可以在用register()方法向Selector注册Channel的时候附加对象。
SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
通过Selector选择通道
一旦向Selector注册了一或多个通道,就可以调用几个重载的select()方法。这些方法返回你所感兴趣的事件(如连接、接受、读或写)已经准备就绪的那些通道。换句话说,如果你对“读就绪”的通道感兴趣,select()方法会返回读事件已经就绪的那些通道。
- int select()
- int select(long timeout)
- int selectNow()
select()阻塞到至少有一个通道在你注册的事件上就绪了。
select(long timeout)和select()一样,除了最长会阻塞timeout毫秒(参数)。
selectNow()不会阻塞,不管什么通道就绪都立刻返回(此方法执行非阻塞的选择操作。如果自从前一次选择操作后,没有通道变成可选择的,则此方法直接返回零。)。
select()方法返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
selectedKeys()
一旦调用了select()方法,并且返回值表明有一个或更多个通道就绪了,然后可以通过调用selector的selectedKeys()方法,访问“已选择键集(selected key set)”中的就绪通道。
当像Selector注册Channel时,Channel.register()方法会返回一个SelectionKey 对象。这个对象代表了注册到该Selector的通道。可以通过selector的selectedKeySet()方法访问这些对象。
Set<SelectionKey> selectionKeys = selector.selectedKeys();
可以遍历这个已选择的键集合来访问就绪的通道。
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
Channel tempChannel = key.channel();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
iterator.remove();
}
这个循环遍历已选择键集中的每个键,并检测各个键所对应的通道的就绪事件。
注意每次迭代末尾的keyIterator.remove()调用。Selector不会自己从已选择键集中移除SelectionKey实例。必须在处理完通道时自己移除。下次该通道变成就绪时,Selector会再次将其放入已选择键集中。
SelectionKey.channel()方法返回的通道需要转型成你要处理的类型,如ServerSocketChannel或SocketChannel等。
wakeUp()
某个线程调用select()方法后阻塞了,即使没有通道已经就绪,也有办法让其从select()方法返回。只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可。阻塞在select()方法上的线程会立马返回。
如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
close()
用完Selector后调用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效。通道本身并不会关闭。
完整的示例
这里有一个完整的示例,打开一个Selector,注册一个通道注册到这个Selector上(通道的初始化过程略去),然后持续监控这个Selector的四种事件(接受,连接,读,写)是否就绪。
Selector selector = Selector.open();
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while(true) {
int readyChannels = selector.select();
if(readyChannels == 0) continue;
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
}
FileChannel
Java NIO中的FileChannel是一个连接到文件的通道。可以通过文件通道读写文件。
FileChannel无法设置为非阻塞模式,它总是运行在阻塞模式下。
打开FileChannel
在使用FileChannel之前,必须先打开它。但是,我们无法直接打开一个FileChannel,需要通过使用一个InputStream、OutputStream或RandomAccessFile来获取一个FileChannel实例。下面是通过RandomAccessFile打开FileChannel的示例:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
从FileChannel读取数据
调用多个read()方法之一从FileChannel中读取数据。
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
首先,分配一个Buffer。从FileChannel中读取的数据将被读到Buffer中。
然后,调用FileChannel.read()方法。该方法将数据从FileChannel读取到Buffer中。read()方法返回的int值表示了有多少字节被读到了Buffer中。如果返回-1,表示到了文件末尾。
向FileChannel写数据
使用FileChannel.write()方法向FileChannel写数据,该方法的参数是一个Buffer。
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put("str".getBytes());
buf.flip();
while(buf.hasRemaining())
channel.write(buf);
注意FileChannel.write()是在while循环中调用的。因为无法保证write()方法一次能向FileChannel写入多少字节,因此需要重复调用write()方法,直到Buffer中已经没有尚未写入通道的字节。
关闭FileChannel
用完FileChannel后必须将其关闭。
channel.close();
position()
有时可能需要在FileChannel的某个特定位置进行数据的读/写操作。可以通过调用position()方法获取FileChannel的当前位置。
也可以通过调用position(long pos)方法设置FileChannel的当前位置。
long pos = channel.position();
channel.position(pos +123);
如果将位置设置在文件结束符之后,然后试图从文件通道中读取数据,读方法将返回-1 —— 文件结束标志。
如果将位置设置在文件结束符之后,然后向通道中写数据,文件将撑大到当前位置并写入数据。这可能导致“文件空洞”,磁盘上物理文件中写入的数据间有空隙。
size()
long fileSize = channel.size();
FileChannel实例的size()方法将返回该实例所关联文件的大小
truncate()
可以使用FileChannel.truncate()方法截取一个文件。截取文件时,文件将指定长度的后面的部分删除。
channel.truncate(1024);
这个例子截取文件的前1024个字节。
force()
FileChannel.force()方法将通道里尚未写入磁盘的数据强制写到磁盘上。出于性能方面的考虑,操作系统会将数据缓存在内存中,所以无法保证写入到FileChannel里的数据一定会即时写到磁盘上。要保证这一点,需要调用force()方法。
force()方法有一个boolean类型的参数,指明是否同时将文件元数据(权限信息等)写到磁盘上。
下面的例子同时将文件数据和元数据强制写到磁盘上:
channel.force(true);
SocketChannel[略]
Java NIO中的SocketChannel是一个连接到TCP网络套接字的通道。可以通过以下2种方式创建SocketChannel:
- 打开一个SocketChannel并连接到互联网上的某台服务器
- 一个新连接到达ServerSocketChannel时,会创建一个SocketChannel
打开 SocketChannel
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
关闭 SocketChannel
当用完SocketChannel之后调用SocketChannel.close()关闭SocketChannel:
socketChannel.close();
从 SocketChannel 读取数据
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = socketChannel.read(buf);
写入 SocketChannel
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put("str".getBytes());
buf.flip();
while(buf.hasRemaining())
channel.write(buf);
非阻塞模式
可以设置 SocketChannel 为非阻塞模式(non-blocking mode).设置之后,就可以在异步模式下调用connect(), read() 和write()了。
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress("127.0.0.1", 80));
while(!socketChannel.finishConnect()){
//wait, or do something else...
}
connect()
非阻塞模式下,write()方法在尚未写出任何内容时可能就返回了。所以需要在循环中调用write()。前面已经有例子了,这里就不赘述了。
read()
非阻塞模式下,read()方法在尚未读取到任何数据时可能就返回了。所以需要关注它的int返回值,它会告诉你读取了多少字节。
非阻塞模式与选择器
非阻塞模式与选择器搭配会工作的更好,通过将一或多个SocketChannel注册到Selector,可以询问选择器哪个通道已经准备好了读取,写入等。Selector与SocketChannel的搭配使用会在后面详讲。
ServerSocketChannel
Java NIO中的 ServerSocketChannel 是一个可以监听新进来的TCP连接的通道, 就像标准IO中的ServerSocket一样。ServerSocketChannel类在 java.nio.channels包中。
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
//do something with socketChannel...
}
打开 ServerSocketChannel
通过调用 ServerSocketChannel.open() 方法来打开ServerSocketChannel.
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
关闭 ServerSocketChannel
通过调用ServerSocketChannel.close() 方法来关闭ServerSocketChannel.
serverSocketChannel.close();
监听新进来的连接
通过 ServerSocketChannel.accept() 方法监听新进来的连接。当 accept()方法返回的时候,它返回一个包含新进来的连接的 SocketChannel。因此, accept()方法会一直阻塞到有新连接到达。
通常不会仅仅只监听一个连接,在while循环中调用 accept()方法。
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
//do something with socketChannel...
}
当然,也可以在while循环中使用除了true以外的其它退出准则。
非阻塞模式
ServerSocketChannel可以设置成非阻塞模式。在非阻塞模式下,accept() 方法会立刻返回,如果还没有新进来的连接,返回的将是null。因此,需要检查返回的SocketChannel是否是null。
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
serverSocketChannel.configureBlocking(false);
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
if(socketChannel != null){
//do something with socketChannel...
}
}
DatagramChannel
Java NIO中的DatagramChannel是一个能收发UDP包的通道。因为UDP是无连接的网络协议,所以不能像其它通道那样读取和写入。它发送和接收的是数据包。
打开 DatagramChannel
这个例子打开的 DatagramChannel可以在UDP端口9999上接收数据包。
DatagramChannel channel = DatagramChannel.open();
channel.socket().bind(new InetSocketAddress(9999));
接收数据
通过receive()方法从DatagramChannel接收数据
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
channel.receive(buf);
receive()方法会将接收到的数据包内容复制到指定的Buffer. 如果Buffer容不下收到的数据,多出的数据将被丢弃。
发送数据
通过send()方法从DatagramChannel发送数据。
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put("str".getBytes());
buf.flip();
int bytesSent = channel.send(buf, new InetSocketAddress("jenkov.com", 80));
这个例子发送一串字符到”jenkov.com”服务器的UDP端口80。 因为服务端并没有监控这个端口,所以什么也不会发生。也不会通知你发出的数据包是否已收到,因为UDP在数据传送方面没有任何保证。
连接到特定的地址
可以将DatagramChannel“连接”到网络中的特定地址的。由于UDP是无连接的,连接到特定地址并不会像TCP通道那样创建一个真正的连接。而是锁住DatagramChannel ,让其只能从特定地址收发数据。当连接后,也可以使用read()和write()方法,就像在用传统的通道一样。只是在数据传送方面没有任何保证。
channel.connect(new InetSocketAddress("jenkov.com", 80));
int bytesRead = channel.read(buf);
int bytesWritten = channel.write(buf);
Pipe
Java NIO 管道是2个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。数据会被写到sink通道,从source通道读取。
这里是Pipe原理的图示: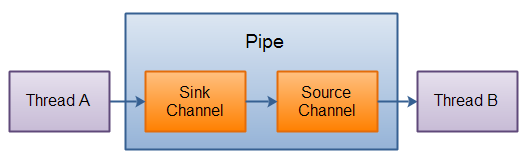
创建管道
通过Pipe.open()方法打开管道。
Pipe pipe = Pipe.open();
向管道写数据
要向管道写数据,需要访问sink通道。通过调用SinkChannel的write()方法,将数据写入SinkChannel。
Pipe.SinkChannel sinkChannel = pipe.sink();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put("str".getBytes());
buf.flip();
while(buf.hasRemaining())
sinkChannel.write(buf);
从管道读取数据
从读取管道的数据,需要访问source通道。调用source通道的read()方法来读取数据。
Pipe.SourceChannel sourceChannel = pipe.source();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = sourceChannel.read(buf);
NIO与IO
我应该何时使用IO,何时使用NIO呢?在本文中会尽量清晰地解析Java NIO和IO的差异、它们的使用场景,以及它们如何影响您的代码设计。
Java NIO和IO的主要区别
IO NIO
面向流 面向缓冲
阻塞IO 非阻塞IO
无 选择器
面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
NIO和IO如何影响应用程序的设计
- 对NIO或IO类的API调用。
- 数据处理。
- 用来处理数据的线程数。
API调用
当然,使用NIO的API调用时看起来与使用IO时有所不同,但这并不意外,因为并不是仅从一个InputStream逐字节读取,而是数据必须先读入缓冲区再处理。
数据处理
使用纯粹的NIO设计相较IO设计,数据处理也受到影响。
在IO设计中,我们从InputStream或 Reader逐字节读取数据。假设你正在处理一基于行的文本数据流,例如:
Name: Anna
Age: 25
Email: [email protected]
Phone: 1234567890
InputStream input = … ; // get the InputStream from the client socket
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String nameLine = reader.readLine();
String ageLine = reader.readLine();
String emailLine = reader.readLine();
String phoneLine = reader.readLine();
请注意处理状态由程序执行多久决定。换句话说,一旦reader.readLine()方法返回,你就知道肯定文本行就已读完, readline()阻塞直到整行读完,这就是原因。你也知道此行包含名称;同样,第二个readline()调用返回的时候,你知道这行包含年龄等。 正如你可以看到,该处理程序仅在有新数据读入时运行,并知道每步的数据是什么。一旦正在运行的线程已处理过读入的某些数据,该线程不会再回退数据(大多如此)。下图也说明了这条原则:(Java IO: 从一个阻塞的流中读数据)
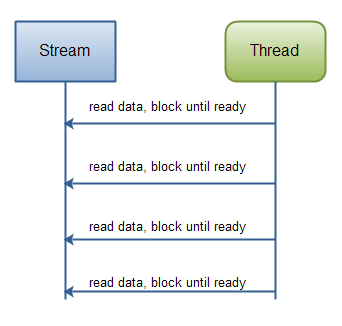
而一个NIO的实现会有所不同。
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
注意第二行,从通道读取字节到ByteBuffer。当这个方法调用返回时,你不知道你所需的所有数据是否在缓冲区内。你所知道的是,该缓冲区包含一些字节,这使得处理有点困难。
假设第一次 read(buffer)调用后,读入缓冲区的数据只有半行,例如,“Name:An”,你能处理数据吗?显然不能,需要等待,直到整行数据读入缓存,在此之前,对数据的任何处理毫无意义。
所以,你怎么知道是否该缓冲区包含足够的数据可以处理呢?好了,你不知道。发现的方法只能查看缓冲区中的数据。其结果是,在你知道所有数据都在缓冲区里之前,你必须检查几次缓冲区的数据。这不仅效率低下,而且可以使程序设计方案杂乱不堪。例如:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
while(!bufferFull(bytesRead)) {
bytesRead = inChannel.read(buffer);
}
bufferFull()方法必须跟踪有多少数据读入缓冲区,并返回真或假,这取决于缓冲区是否已满。换句话说,如果缓冲区准备好被处理,那么表示缓冲区满了。
bufferFull()方法扫描缓冲区,但必须保持在bufferFull()方法被调用之前状态相同。如果没有,下一个读入缓冲区的数据可能无法读到正确的位置。这是不可能的,但却是需要注意的又一问题。
如果缓冲区已满,它可以被处理。如果它不满,并且在你的实际案例中有意义,你或许能处理其中的部分数据。但是许多情况下并非如此。下图展示了“缓冲区数据循环就绪”:(Java NIO:从一个通道里读数据,直到所有的数据都读到缓冲区里)
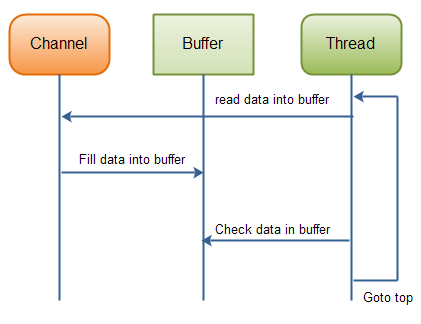
用来处理数据的线程数
NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
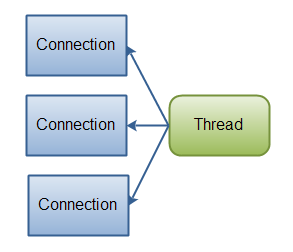
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,实现NIO的服务器可能是一个优势。同样,如果你需要维持许多打开的连接到其他计算机上,如P2P网络中,使用一个单独的线程来管理你所有出站连接,可能是一个优势。一个线程多个连接的设计方案如下图所示:(Java NIO: 单线程管理多个连接)
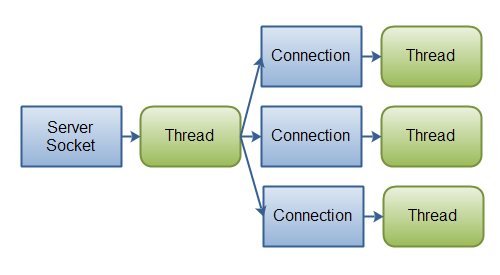
如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO服务器实现可能非常契合。下图说明了一个典型的IO服务器设计:(Java IO: 一个典型的IO服务器设计 一个连接通过一个线程处理)
Path
Path接口是java NIO2的一部分。首次在java 7中引入。Path接口在java.nio.file包下,所以全称是java.nio.file.Path。 java中的Path表示文件系统的路径。可以指向文件或文件夹。也有相对路径和绝对路径之分。绝对路径表示从文件系统的根路径到文件或是文件夹的路径。相对路径表示从特定路径下访问指定文件或文件夹的路径。相对路径的概念可能有点迷糊。不用担心,我将在本文的后面详细介绍相关细节。
不要将文件系统的path和操作系统的环境变量path搞混淆。java.nio.file.Path接口和操作系统的path环境变量没有任何关系。
在很多方面,java.nio.file.Path接口和java.io.File有相似性,但也有一些细微的差别。在很多情况下,可以用Path来代替File类。
创建Path实例
为了使用java.nio.file.Path实例,必须首先创建它。可以使用Paths 类的静态方法Paths.get()来产生一个实例。
import java.nio.file.Path;
import java.nio.file.Paths;
Path path = Paths.get("c:\\data\\myfile.txt");
请注意例子开头的两个import语句。想要使用Paths类和Path接口,必须首先引入相应包。其次,其使用了Paths.get方法创建了Path的实例。它是一个工厂方法。
创建绝对路径Path
调用传入绝对路径当做参数的Paths.get()工厂方法,就可以生成绝对路径Path。
Path path = Paths.get("c:\\data\\myfile.txt");
示例中的绝对路径是c:\data\myfile.txt。有两个\字符的原因是第一个\是转义字符,表示紧跟着它的字符需要被转义。\表示需要向字符串中写入一个\字符。
上文示例的path是windows下的路径。在Unix系统(Linux,MacOS,FreeBSD等)中,上文中的path是这样的:
Path path = Paths.get("/home/jakobjenkov/myfile.txt");
/home/jakobjenkov/myfile.txt就称作绝对路径。
如果把以/开头path的格式运行在windows系统中,系统会将其解析为相对路径。例如:
/home/jakobjenkov/myfile.txt
将会被解析为路径是在C盘。对应的绝对路径是:C:/home/jakobjenkov/myfile.txt
创建相对路径Path
对路径指从一个已确定的路径开始到某一文件或文件夹的路径。将确定路径和相对路径拼接起来就是相对路径对应的绝对路径地址。
java NIO Path类也能使用相对路径。可以通过Paths.get(basePath, relativePath)创建一个相对路径Path。示例如下:
Path projects = Paths.get("d:\\data", "projects");
Path file = Paths.get("d:\\data", "projects\\a-project\\myfile.txt");
第一个例子创建了一个指向d:\data\projects文件夹的实例。第二个例子创建了一个指向 d:\data\projects\a-project\myfile.txt 文件的实例。
当使用相对路径的时候,可以使用如下两种特别的符号。它们是:
- .
- ..
.表示当前路径。例如,如果以如下方式创建一个相对路径:
Path currentDir = Paths.get(".");
System.out.println(currentDir.toAbsolutePath());
创建的Path实例对应的路径就是运行这段代码的项目工程目录。
如果.用在路径中,则其表示的就是当前路径下。示例:
Path currentDir = Paths.get("d:\\data\\projects\.\a-project");
对应的就是此路径 d:\data\projects\a-project
..表示父类目录。示例:
Path parentDir = Paths.get("..");
Path对应的路径是当前运行程序目录的上级目录。
如果在path中使用..,表示上级目录的含义。例如:
String path = "d:\\data\\projects\\a-project\\..\\another-project";
Path parentDir2 = Paths.get(path);
对应的绝对路径地址为: d:\data\projects\another-project
在a-project目录后面的..符号,将指向的目录修改为projects目录,因此,最终path指向another-project目录。
.和..都可以在Paths.get()的双形参方法中使用。示例:
Path path1 = Paths.get("d:\\data\\projects", ".\\a-project");
Path path2 = Paths.get("d:\\data\\projects\\a-project", "..\\another-project");
Path.normalize()
Path 的normalize()方法可以标准化路径。标准化的含义是路径中的.和..都被去掉,指向真正的路径目录地址。下面是Path.normalize()示例:
String originalPath = "d:\\data\\projects\\a-project\\..\\another-project";
Path path1 = Paths.get(originalPath);
System.out.println("path1 = " + path1);
Path path2 = path1.normalize();
System.out.println("path2 = " + path2);
输出结果如下:
path1 = d:\data\projects\a-project\..\another-project
path2 = d:\data\projects\another-project
Files
Java NIO中的Files类(java.nio.file.Files)提供了多种操作文件系统中文件的方法。本节教程将覆盖大部分方法。Files类包含了很多方法,所以如果本文没有提到的你也可以直接查询JavaDoc文档。
java.nio.file.Files类是和java.nio.file.Path相结合使用的,所以在用Files之前确保你已经理解了Path类。
Files.exists()
Files.exits()方法用来检查给定的Path在文件系统中是否存在。 在文件系统中创建一个原本不存在的Payh是可行的。例如,你想新建一个目录,那么先创建对应的Path实例,然后创建目录。
由于Path实例可能指向文件系统中的不存在的路径,所以需要用Files.exists()来确认。
下面是一个使用Files.exists()的示例:
Path path = Paths.get("data/logging.properties");
boolean pathExists = Files.exists(path, new LinkOption[]{LinkOption.NOFOLLOW_LINKS});
这个示例中,我们首先创建了一个Path对象,然后利用Files.exists()来检查这个路径是否真实存在。
注意Files.exists()的的第二个参数。他是一个数组,这个参数直接影响到Files.exists()如何确定一个路径是否存在。在本例中,这个数组内包含了LinkOptions.NOFOLLOW_LINKS,表示检测时不包含符号链接文件。
Files.createDirectory()
Files.createDirectory()会创建Path表示的路径,下面是一个示例:
Path path = Paths.get("data/subdir");
try {
Path newDir = Files.createDirectory(path);
} catch(FileAlreadyExistsException e){
// the directory already exists.
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
第一行创建了一个Path实例,表示需要创建的目录。接着用try-catch把Files.createDirectory()的调用捕获住。如果创建成功,那么返回值就是新创建的路径。
如果目录已经存在了,那么会抛出java.nio.file.FileAlreadyExistException异常。如果出现其他问题,会抛出一个IOException。比如说,要创建的目录的父目录不存在,那么就会抛出IOException。父目录指的是你要创建的目录所在的位置。也就是新创建的目录的上一级父目录。
Files.copy()
Files.copy()方法可以吧一个文件从一个地址复制到另一个位置。
Path sourcePath = Paths.get("data/logging.properties");
Path destinationPath = Paths.get("data/logging-copy.properties");
try {
Files.copy(sourcePath, destinationPath);
} catch(FileAlreadyExistsException e) {
//destination file already exists
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
这个例子当中,首先创建了原文件和目标文件的Path实例。然后把它们作为参数,传递给Files.copy(),接着就会进行文件拷贝。
如果目标文件已经存在,就会抛出java.nio.file.FileAlreadyExistsException异常。类似的吐过中间出错了,也会抛出IOException。
覆盖已经存在的文件(Overwriting Existing Files)
copy操作可以强制覆盖已经存在的目标文件。
Path sourcePath = Paths.get("data/logging.properties");
Path destinationPath = Paths.get("data/logging-copy.properties");
try {
Files.copy(sourcePath, destinationPath, StandardCopyOption.REPLACE_EXISTING);
} catch(FileAlreadyExistsException e) {
//destination file already exists
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
注意copy方法的第三个参数,这个参数决定了是否可以覆盖文件。
Files.move()
Java NIO的Files类也包含了移动的文件的接口。移动文件和重命名是一样的,但是还会改变文件的目录位置。java.io.File类中的renameTo()方法与之功能是一样的。
Path sourcePath = Paths.get("data/logging-copy.properties");
Path destinationPath = Paths.get("data/subdir/logging-moved.properties");
try {
Files.move(sourcePath, destinationPath,
StandardCopyOption.REPLACE_EXISTING);
} catch (IOException e) {
//moving file failed.
e.printStackTrace();
}
首先创建源路径和目标路径的,原路径指的是需要移动的文件的初始路径,目标路径是指需要移动到的位置。
这里move的第三个参数也允许我们覆盖已有的文件。
Files.delete()
Files.delete()方法可以删除一个文件或目录:
Path path = Paths.get("data/subdir/logging-moved.properties");
try {
Files.delete(path);
} catch (IOException e) {
//deleting file failed
e.printStackTrace();
}
首先创建需要删除的文件的path对象。接着就可以调用delete了。
Files.walkFileTree()
Files.walkFileTree()方法具有递归遍历目录的功能。walkFileTree接受一个Path和FileVisitor作为参数。Path对象是需要遍历的目录,FileVistor则会在每次遍历中被调用。
下面先来看一下FileVisitor这个接口的定义:
public interface FileVisitor {
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException;
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException;
}
FileVisitor需要调用方自行实现,然后作为参数传入walkFileTree().FileVisitor的每个方法会在遍历过程中被调用多次。如果不需要处理每个方法,那么可以继承他的默认实现类SimpleFileVisitor,它将所有的接口做了空实现。
下面看一个walkFileTree()的示例:
Files.walkFileTree(path, new FileVisitor<Path>() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("pre visit dir:" + dir);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("visit file: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.out.println("visit file failed: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
System.out.println("post visit directory: " + dir);
return FileVisitResult.CONTINUE;
}
});
FileVisitor的方法会在不同时机被调用: preVisitDirectory()在访问目录前被调用。postVisitDirectory()在访问后调用。
visitFile()会在整个遍历过程中的每次访问文件都被调用。他不是针对目录的,而是针对文件的。visitFileFailed()调用则是在文件访问失败的时候。例如,当缺少合适的权限或者其他错误。
上述四个方法都返回一个FileVisitResult枚举对象。具体的可选枚举项包括:
- CONTINUE
- TERMINATE
- SKIP_SIBLINGS
- SKIP_SUBTREE
返回这个枚举值可以让调用方决定文件遍历是否需要继续。 CONTINE表示文件遍历和正常情况下一样继续。
TERMINATE表示文件访问需要终止。
SKIP_SIBLINGS表示文件访问继续,但是不需要访问其他同级文件或目录。
SKIP_SUBTREE表示继续访问,但是不需要访问该目录下的子目录。这个枚举值仅在preVisitDirectory()中返回才有效。如果在另外几个方法中返回,那么会被理解为CONTINE。
Searching For Files
下面看一个例子,我们通过walkFileTree()来寻找一个README.txt文件:
Path rootPath = Paths.get("data");
String fileToFind = File.separator + "README.txt";
try {
Files.walkFileTree(rootPath, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
String fileString = file.toAbsolutePath().toString();
//System.out.println("pathString = " + fileString);
if(fileString.endsWith(fileToFind)){
System.out.println("file found at path: " + file.toAbsolutePath());
return FileVisitResult.TERMINATE;
}
return FileVisitResult.CONTINUE;
}
});
} catch(IOException e){
e.printStackTrace();
}
Deleting Directies Recursively
Files.walkFileTree()也可以用来删除一个目录以及内部的所有文件和子目。Files.delete()只用用于删除一个空目录。我们通过遍历目录,然后在visitFile()接口中三次所有文件,最后在postVisitDirectory()内删除目录本身。
Path rootPath = Paths.get("data/to-delete");
try {
Files.walkFileTree(rootPath, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("delete file: " + file.toString());
Files.delete(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
System.out.println("delete dir: " + dir.toString());
return FileVisitResult.CONTINUE;
}
});
} catch(IOException e){
e.printStackTrace();
}
Additional Methods in the Files Class
java.nio.file.Files类还有其他一些很有用的方法,比如创建符号链接,确定文件大小以及设置文件权限等。具体用法可以查阅JavaDoc中的API说明。