记一次锁等待超时排查(Gap Lock、Lock wait timeout exceeded)
近日线上服务的日志监控到了锁等待超时的情况,结合日志以及查看事务表
select * from information_schema.innodb_trx;
比较简单就定位到了相关的表与SQL语句。
表结构,隐去了无关的字段
CREATE TABLE `threshold` (
`id` varchar(50) NOT NULL,
`device_id` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
执行较长时间的SQL、以及等待锁释放的SQL
delete from threshold where device_id in ...
单表数据约为250w,这个数据量对于MySQL应该不存在较大问题。初步分析可以确定执行过慢原因为device_id列没有建立索引,而通过in的方式删除又是全表扫描,可能在这里耗时过多。由于in中条件并不多,直觉上又以为只有符合条件的数据才被加锁,所以还是没有想明白为什么会这么慢。于是通过explain查看SQL的执行,发现无论in中条件为多少个,该表的全部数据都被加了锁!
通过查阅、补充关于MySQL中的数据加锁处理分析的知识,最后解答了自己的疑惑,于是就有了这篇记录。
开始之前
默认都有足够的数据库相关的知识,这里先罗列一些涉及到的点
查看事务锁等待超时时间
mysql> SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 50 |
+--------------------------+-------+
InnoDB Locking
S锁:共享锁
X锁:排他锁
IS:意向共享锁
IX:意向排他锁
表级锁定类型兼容性(加了某个锁的记录能不能加另一个锁)
| X | IX | S | IS | |
|---|---|---|---|---|
| X | Conflict | Conflict | Conflict | Conflict |
| IX | Conflict | Compatible | Conflict | Compatible |
| S | Conflict | Conflict | Compatible | Compatible |
| IS | Conflict | Compatible | Compatible | Compatible |
MVVC、快照读、当前读
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议MVCC。在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本(有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
快照读:简单的select操作,属于快照读,不加锁。
select * from table where ?;
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where ? lock in share mode; --
select * from table where ? for update;
insert into table values (…);
update table set ? where ?;
delete from table where ?;
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁外,其他的操作,都加的是X锁。

Cluster Index 聚簇索引
InnoDB存储引擎的数据组织方式,是聚簇索引表:完整的记录,存储在主键索引中,通过主键索引,就可以获取记录所有的列。关于聚簇索引表的组织方式,可以参考MySQL的官方文档:Clustered and Secondary Indexes 。本文假设读者对这个,已经有了一定的认识,就不再做具体的介绍。接下来的部分,主键索引/聚簇索引 两个名称,会有一些混用,望读者知晓。
Two-Phase Locking

Isolation Level 隔离级别
- Read Uncommited
可以读取未提交记录 - Read Committed
对读取到的记录加锁(记录锁),存在幻读现象。 - Repeatable Read
针对当前读,RR隔离级别保证对读取到的记录加锁(记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入(间隙锁),不存在幻读现象。 - Serializable
从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加S锁,写加X锁。Serializable隔离级别下,读写冲突,因此并发度急剧下降,在MySQL/InnoDB下不建议使用。
MySQL默认隔离级别
mysql> SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
SQL分析
何登成大牛的博客中其实已经涉及了常见的SQL情况,对应于“组合八:id无索引+RR”,但是完整的文章还是非常建议读一读的,参见引用参考中的链接。
这里只列出符合我本次遇到的情况。
在RR的隔离级别,device_id列没有索引。删除语句用不到二级索引,只能进行全表扫描。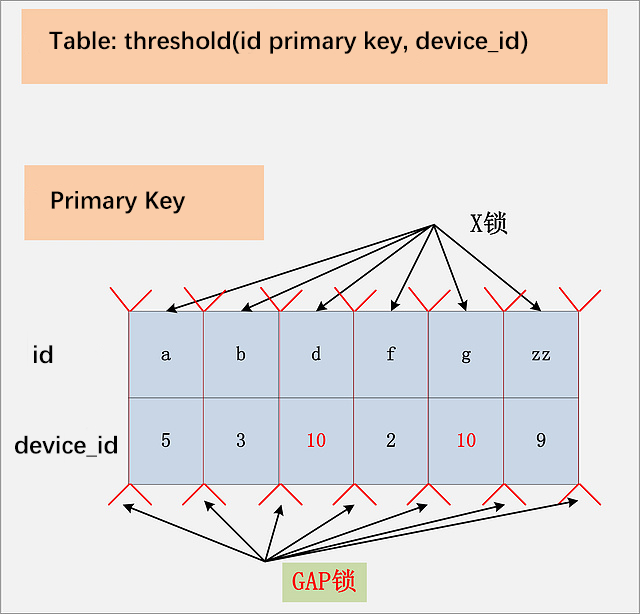
首先,聚簇索引上的所有记录,都被加上了X锁。其次,聚簇索引每条记录间的间隙(GAP),也同时被加上了GAP锁。
这个多出来的GAP锁,就是RR隔离级别,相对于RC隔离级别,不会出现幻读的关键。确实,GAP锁锁住的位置,也不是记录本身,而是两条记录之间的GAP。所谓幻读,就是同一个事务,连续做两次当前读 (例如:select * from threshold where device_id = 10 for update;),那么这两次当前读返回的是完全相同的记录 (记录数量一致,记录本身也一致),第二次的当前读,不会比第一次返回更多的记录 (幻象)。
为了保证两次当前读返回一致的记录,那就需要在第一次当前读与第二次当前读之间,其他的事务不会插入新的满足条件的记录并提交。为了实现这个功能,GAP锁应运而生。由于BTREE索引的有序性,只要锁住符合查询条件的记录的上一条记录至本记录,以及本记录至下一条记录这两个间隔,就可以了。
但是对于本例(线上遇到的)这种情况,就很恐怖了,删除时相当于加了250w个X锁,250w+1个GAP锁,所以整个SQL执行过程才会这么慢。
这里需要说明的是,对于RC隔离级别的情况,若device_id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
对于我们RR隔离级别的情况,如果想要做到,就还需要设置innodb_locks_unsafe_for_binlog为ON,默认为OFF,注意这样也会带来别的问题,不建议使用。
mysql> SHOW VARIABLES LIKE 'innodb_locks_unsafe_for_binlog';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_locks_unsafe_for_binlog | OFF |
+--------------------------------+-------+
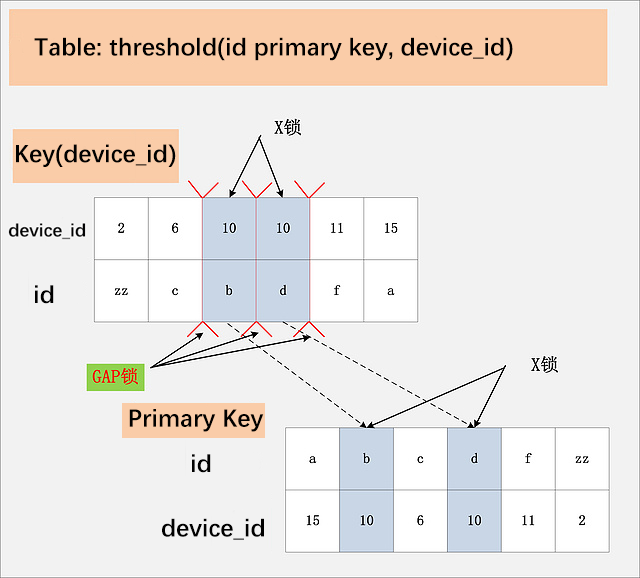
这里正确的做法是给device_id列加上索引。这时只会在device_id列索引上加上X锁与GAP锁,同时这些记录对应的主键索引上的记录加X锁,与不加索引时相比,减少了极大的开销。
小结
直接看问题的解决方式,其实是非常简单的,但是更重要的是知道如何做,为何做。而对于实际业务来说,存在的问题就是索引建立不得当。除了本次遇到的,之前也遇到过类似索引相关的问题,如没有建立索引、建立无效索引(没有被命中)、以及建立过多的索引,导致索引数据比记录本身还大很多,造成空间的浪费。在开发过程中索引应该是为了实际需要而建立,要结合SQL去建立或者说优化SQL。不应该为了建索引而建索引。
引用参考