定义类
以 class 为关键字,声明类。
class Player
可见性与封装
Java 和 Kotlin 函数可见性修饰符对照
| 修饰符 | Java | Kotlin |
|---|---|---|
| public | 所有类可见 | 所有类可见(默认) |
| private | 当前类可见 | 当前类可见 |
| protected | 当前类、子类、同一包路径下的类可见 | 当前类、子类可见 |
| default | 同一包路径下的类可见(默认) | 无 |
| internal | 无 | 同一模块中的类可见 |
属性 getter 与 setter
针对定义的每一个属性,Kotlin 会产生一个 field、一个 getter,以及一个 setter(如果需要的话)。
field 用来存储属性数据。不能直接定义 field,Kotlin 会封装 field,保护它里面的数据, 只暴露给 getter 和 setter 使用。
属性的 getter 方法决定如何读取属性值。每个属性都有 getter 方法。
setter 方法决定你如何给属性赋值,所以,只有可变属性才会有 setter 方法。换句话说,就是 以 var 关键字定义的属性才有 setter 方法。
Kotlin 会自动提供默认的 getter 和 setter 方法,但在需要控制如何读写属性数据时,也可以自定义。这种自定义行为叫作覆盖 getter 和 setter 方法。
class Player {
var name = "madrigal"
get() = field.capitalize()
set(value) {
field = value.trim()
}
}
fun main() {
val player = Player()
println(player.name)
player.name = " hikari "
println(player.name)
}
field 关键字自动指向 Kotlin 管理着的支持字段(backing field)。getter 和 setter 方法使用支持字段来读取属性值。field 也只能在 getter 或 setter 方法里使用。
属性不同于函数里定义的局部变量。属性定义属于类级别的。这也就是说,只要没有可见性限制,某个类里定义的属性数据都能被其他类访问到。
某个属性的 getter 和 setter 方法的可见性不能比该属性自身的可见性更宽松。可以通过 getter 或 setter 方法来限制属性的访问,但它们不是用来让属性更加暴露的。
计算属性
class Dice() {
val rolledValue
get() = (1..6).shuffled().first()
}
fun main() {
val myD6 = Dice()
repeat(3) { println(myD6.rolledValue) }
}
计算属性是通过一个覆盖的 get 和(或)set 运算符来定义的,这时 field 就不需要了。也就是说,Kotlin 在碰到这种情况时就不会产生 field。
类与对象
Kotlin 中实例化一个类的时候不需要 new 关键字。
class Person {
var name = ""
var age = 0
fun eat() {
println("$name is eating. He is $age years old.")
}
}
fun main() {
val p = Person()
p.name = "Jack"
p.age = 17
p.eat()
}
继承
Kotlin 中任何一个非抽象类默认都是不可以继承的,相当于 Java 中给类声明了 final 关键字。Kotlin 中抽象类和 Java 中并无区别。之所以这么设计,与 val 关键字的原因差不多。类和变量一样,最好都是不可变的,如果一个类可以继承,它无法预知子类会如何实现,因此可能会存在一些未知的风险。《Effective Java》中明确提到,如果一个类不是专门为继承而设计的,那么就应该主动将它加上 final 声明,禁止它可以被继承。
Kotlin 中每一个类都会继承一个共同的叫作 Any 的超类。
Kotlin 中使用 is 关键字检查某个对象的类型,使用 as 关键字来实现类型转换。
在类前加上 open 关键字,这个类就允许被继承了。继承的关键字是 :。
open class Person {
...
}
class Student : Person() {
var sno = ""
var grade = 0
}
父类的函数、属性如果允许被覆盖,同样要使用 open 修饰。子类里使用 override 关键字修饰覆盖的函数、属性。要想某个函数不被子类覆盖,就使用 final 关键字修饰它。
主构造函数
每个类都默认会有一个不带参数的主构造函数,也可以显式的指名参数。
主构造函数没有函数体,直接定义在类的后面。
class Student(val sno: String, val grade: Int) : Person() {
}
fun main() {
val student = Student("123", 5)
}
这就表明在对 Student 类实例化时,必须传入构造函数中的所有参数(由于不用重新赋值,所以声明用了 val)。
主构造函数没有函数体,如果需要在主构造函数中编写逻辑,可以写在 init 结构体中。
class Student(val sno: String, val grade: Int) : Person() {
init {
println("sno: $sno")
println("grade: $grade")
}
}
子类中的构造函数必须调用父类的构造函数。子类的主构造函数调用父类中的哪个构造函数,在继承的时候通过括号来指定。
Person 类后面的一对空括号表示 Student 类的主构造函数在初始化的时候会调用 Person 类的无参构造函数。即使在无参数的情况下,这对括号也不能省略。所以如果修改 Person 类的主构造函数为带有参数的形式,Student 类也要做相应的修改。
open class Person(val name: String, val age: Int) {
...
}
class Student(val sno: String, val grade: Int, name: String, age: Int) : Person(name, age) {
}
fun main() {
val student = Student("123", 5, "Tom", 16)
}
Student 类的主构造函数在增加 name 和 age 这两个字段时,不能声明为 val 。
因为声明成 val 或 var 的参数将会自动成为该类的字段,这就会导致与父类中同名的 name 和 age 字段造成冲突。这里不加任何关键字,作用域仅限定在主构造函数中即可。
为便于识别,临时变量——包括仅引用一次的参数——通常都会以下划线开头的名字命名。
次构造函数
一个类中只能有一个主构造函数(最多一个,可以没有),可以有多个次构造函数,次构造函数具有函数体。
Kotlin 规定当一个类既有主构造函数,又有次构造函数时,所有的次构造函数都必须调用主构造函数(包括间接调用)。
次构造函数不能用来像主构造函数那样定义属性。类属性必须定义在主构造函数里,或者至少要定义在类层级。
class Student(val sno: String, val grade: Int, name: String, age: Int) : Person(name, age) {
constructor(name: String, age: Int) : this("", 0, name, age) {
}
constructor() : this("", 0) {
}
}
fun main() {
val student1 = Student()
val student2 = Student("Tom", 16)
val student3 = Student("123", 5, "Tom", 16)
}
类中只有次构造函数
当一个类没有显式地定义主构造函数,且定义了次构造函数时,它就是没有主构造函数的。
class Student : Person {
constructor(name: String, age: Int) : super(name, age) {
}
}
此时的 Student 类是没有主构造函数的,既然没有主构造函数,继承 Person 类时也就不需要加上括号了。
因为此时不存在 Student 类的主构造函数要指定调用父类哪个构造函数的问题了。
同时由于 Student 类没有主构造函数,次构造函数就必须通过 super 直接调用父构造函数了。
初始化
初始化块
初始化块代码会在构造类实例时执行。设置变量或值,以及执行有效性检查,如检查传给某构造函数的值是否有效,这些都可以交给初始化块去做。
class Player(
_name: String,
var healthPoints: Int = 100,
val isBlessed: Boolean,
private val isImmortal: Boolean
) {
var name = _name
get() = field.capitalize()
private set(value) {
field = value.trim()
}
init {
require(healthPoints > 0) { "healthPoints must be greater than zero." }
require(name.isNotBlank()) { "Player must have a name." }
}
constructor(name: String) : this(
name,
isBlessed = true,
isImmortal = false
) {
if (name.toLowerCase() == "kar") {
healthPoints = 40
}
}
}
初始化顺序
class Player(_name: String, val health: Int) {
val race = "DWARF"
var town = "Bavaria"
val name = _name
val alignment: String
private var age = 0
init {
println("initializing player")
alignment = "GOOD"
}
constructor(_name: String) : this(_name, 100) {
town = "The Shire"
}
}
fun main() {
Player("Madrigal")
}
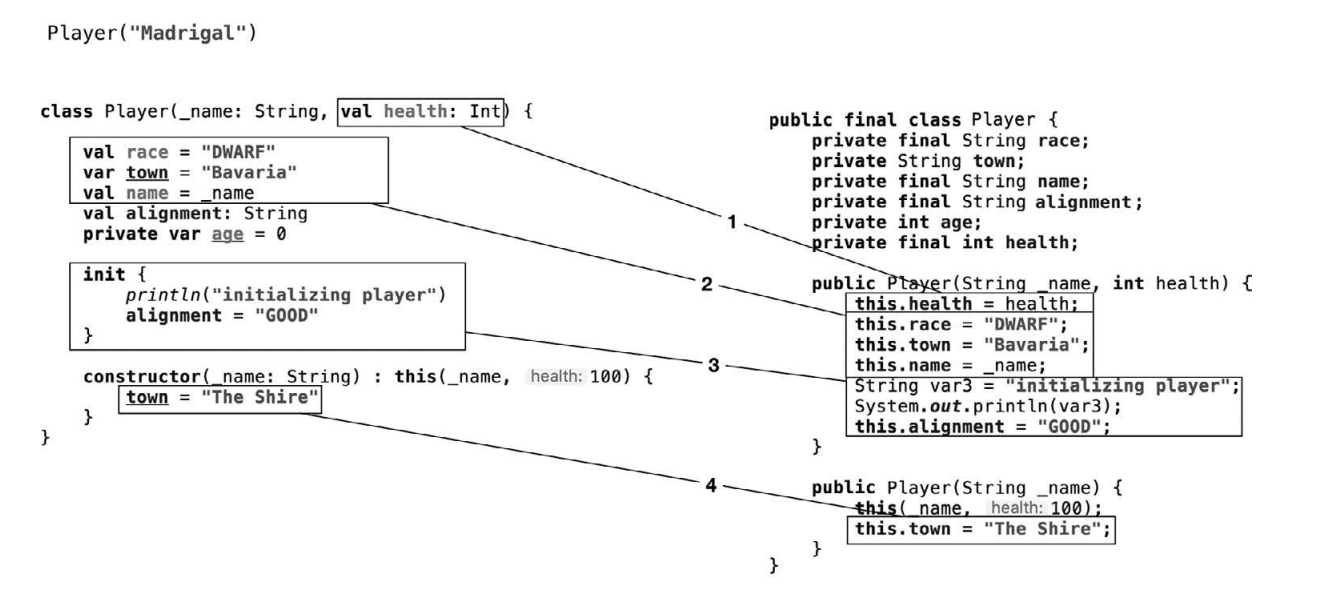
- 主构造函数里声明的属性。
- 类级别的属性赋值。
- init 初始化块里的属性赋值和函数调用。
- 次构造函数里的属性赋值和函数调用。
init 初始化块(线条 3)和类级别的属性赋值(线条 2)的顺序取决于定义的先后。如果 init 初始化块定义在类级别的属性赋值之前,那么它就比类级别的属性赋值早一步初始化。
有一个 age 属性没有在 Java 构造函数里初始化,虽然它处在类属性级别。这是因为它的值是 0。Java 基本类型 int 的默认值就是 0,所以赋值就没必要了,编译器为了优化初始化代码,直接就忽略了它。
延迟初始化
对于任何 var 属性声明,都可以加上 lateinit 关键字。这样 Kotlin 编译器会允许你延后初始化属性。
class Player {
lateinit var alignment: String
fun determineFate() {
alignment = "Good"
}
fun proclaimFate() {
if (::alignment.isInitialized) println(alignment)
}
}
使用 lateinit 关键字就相当于你和自己做了个约定:我会在用它之前负责初始化的。如果在变量还没有初始化的情况下就直接使用它,程序一定会崩溃,并且抛出一个 UninitializedPropertyAccessException 异常。
可以通过 ::alignment.isInitialized 来判断 alignment 是否已经初始化。
最好少用 isInitialized 检查。如果对每个延迟初始化变量都使用 isInitialized 检查,那就和使用一个可空类型变量没什么区别。
惰性初始化
惰性初始化是指可以暂时不初始化某个变量,直到首次使用它。惰性初始化在 Kotlin 里是使用一种叫代理的机制来实现的。代理负责约定属性该如何初始化。
使用代理要用到 by 关键字。Kotlin 标准库里有一些预先配置好的代理可用,lazy 就是其中一个。惰性初始化会用到 lambda 表达式,在表达式里定义属性初始化需要执行的代码。
class Player(_name: String, val health: Int) {
val race = "DWARF"
var town = "Bavaria"
val name = _name
val alignment: String
private var age = 0
val hometown by lazy { selectHometown() }
...
private fun selectHometown() = File("towns.txt")
.readText()
.split("\n")
.shuffled()
.first()
}
lazy 的 lambda 表达式中的所有代码都会被执行一次且只会执行一次。
object 关键字
使用 object 关键字,可以定义一个单例类。
使用 object 关键字有三种方式:对象声明(object declaration)、对象表达式(object expression) 和伴生对象(companion object)。
对象声明
object A {
...
}
对象表达式
有时候不一定非要定义一个新的命名类不可。也许需要某个现有类的一种变体实例,但只需用一次就行了。对于这种用完就丢的类实例,连命名都可以省了。
open class A {
open fun load() = "A load..."
}
val abandonedA = object : A() {
override fun load() = "You anticipate applause, but no one is here..."
}
在这个对象表达式定义体里,可以覆盖 A 类里定义的属性和函数,也可以添加新的属性和函数。
这个匿名类依然遵循 object 关键字的规则,一旦实例化,该匿名类只能有唯一一个实例存在。
它的生命周期或作用范围要远远小于命名单例。取决于在哪里定义,对象表达式会受副作用影响而有不同的初始化表现。如果定义在独立文件里,对象表达式会立即初始化;如果定义在另一个类里,那么只有包含它的类初始化时,对象表达式才会被初始化。
伴生对象
使用 companion 修饰符,可以在一个类定义里声明一个伴生对象。一个类里只能有一个伴生对象。
伴生对象初始化分两种情况。
第一种,包含伴生对象的类初始化时,伴生对象就会被初始化。由于这种相伴关系,伴生对象就适合用来存放和类定义有上下文关系的单例数据。
第二种,只要直接访问伴生对象的某个属性或函数,就会触发伴生对象的初始化。伴生对象本质上依然是个对象声明,所以不需要使用类实例来访问它内部定义的函数或属性。
class WorldMap {
companion object { // 伴生对象
private const val MAPS_FILEPATH = "world.maps"
fun load() = File(MAPS_FILEPATH).readBytes()
}
}
// 调用
WorldMap.load()
数据类
Kotlin 中的所有类都会继承 Any 类。所以可以通过任何实例使用 Any 类里定义的函数。这些函数包括 toString、equals 和 hashCode 等。
Any 提供了所有这些函数的默认实现。不过这些默认实现都比较原始,满足不了个性化需求。数据类提供了这些函数的个性化实现。
使用 data 关键字定义数据类。
data class Coordinate(val x: Int, val y: Int) {
val isInBounds = x >= 0 && y >= 0
}
fun main() {
val c1 = Coordinate(1, 0)
val c2 = Coordinate(1, 0)
val c3 = c1.copy(x = 2) // 数据类提供的 copy 函数
val (x, y) = Coordinate(3, 5) // 解构声明
// 基于类的主构造函数中定义的属性的更友好的展示
println(c1)
// 基于类的主构造函数中定义的属性来判断相等性
println(c1 == c2)
println(c3)
println("x=$x, y=$y")
}
// print
Coordinate(x=1, y=0)
true
Coordinate(x=2, y=0)
x=3, y=5
一个类要成为数据类,要符合一定条件:
- 数据类必须有至少带一个参数的主构造函数
- 数据类主构造函数的参数必须是 val 或 var
- 数据类不能使用 abstract、open、sealed 和 inner 修饰符
枚举类
使用 enum 关键字定义枚举类。
enum class Direction {
NORTH,
EAST,
SOUTH,
WEST
}
给 Direction 枚举类添加一个主构造函数,定义一个 Coordinate 属性。因为枚举类的构造函数带参数,所以定义每个枚举常量时,都要传入 Coordinate 对象,调用构造函数。
enum class Direction(private val coordinate: Coordinate) {
NORTH(Coordinate(0, -1)),
EAST(Coordinate(1, 0)),
SOUTH(Coordinate(0, 1)),
WEST(Coordinate(-1, 0));
fun updateCoordinate(playerCoordinate: Coordinate) =
Coordinate(
playerCoordinate.x + coordinate.x,
playerCoordinate.y + coordinate.y
)
}
// 调用
val updateCoordinate = Direction.EAST.updateCoordinate(Coordinate(1, 0))
代数数据类型
代数数据类型(ADT,algebraic data type)可以用来表示一组子类型的闭集。
实际上,枚举类就是一种简单的 ADT。
enum class StudentStatus {
NOT_ENROLLED,
ACTIVE,
GRADUATED
}
class Student(var status: StudentStatus)
fun studentMessage(status: StudentStatus): String {
// 'when' expression must be exhaustive, add necessary 'ACTIVE', 'GRADUATED' branches or 'else' branch instead
return when (status) {
StudentStatus.NOT_ENROLLED -> "Please choose a course."
}
}
报错提醒未处理全部的情况。
对于代数数据类型,编译器会检查代码处理是否有遗漏, 因为代数数据类型表示的是一组子类型的闭集。
fun studentMessage(status: StudentStatus): String {
return when (status) {
StudentStatus.NOT_ENROLLED -> "Please choose a course."
StudentStatus.ACTIVE -> "Welcome, student!"
StudentStatus.GRADUATED -> "Congratulations!"
}
}
密封类
对于更复杂的 ADT,可以使用 Kotlin 的密封类(sealed class)来实现更复杂的定义。
密封类可以用来定义一个类似于枚举类的 ADT,但可以更灵活地控制某个子类型。
使用 sealed 关键字定义密封类。
sealed class StudentStatus {
object NotEnrolled : StudentStatus()
class Active(val courseId: String) : StudentStatus()
object Graduated : StudentStatus()
}
class Student(var status: StudentStatus)
fun studentMessage(status: StudentStatus): String {
return when (status) {
is StudentStatus.NotEnrolled -> "Please choose a course!"
is StudentStatus.Active -> "You are enrolled in: ${status.courseId}"
is StudentStatus.Graduated -> "Congratulations!"
}
}
当 when 语句中传入一个密封类变量作为条件的时候,Kotlin 会自动检查该密封类有那些子类,并强制要求将每一个子类所对应的条件全部处理。
密封类及其所有子类只能定义在同一个文件的顶层位置,不能嵌套在其他类中,这是密封类底层的实现机制所限制的。