Java 线程和虚拟线程
JEP 444: Virtual Threads
https://openjdk.org/jeps/444
动机
首先考虑一个问题,JVM 中的线程模型是用户级的么?
这个问题只能针对具体 JVM 实现来回答,在 JVM 规范里是没有规定的,具体实现用 1:1(内核线程)、N:1(用户态线程)、M:N(混合)模型的任何一种都可以。
Java 并不暴露出不同线程模型的区别,上层应用是感知不到差异的,只是性能特性会不太一样。
Java SE 最常用的 JVM 是 Oracle/Sun 研发的 HotSpot VM。
在这个 JVM 的较新版本所支持的所有平台上,它都是使用 1:1 线程模型的。
Solaris 系统是一个特例,HotSpot VM 在 Solaris 上支持多对多和一对一,参考 Java(TM) and Solaris(TM) Threading
一直以来 Java 并发单元是 Thread,而每个 Thread 都提供了一个堆栈来存储局部变量和方法调用,以及线程上下文等相关信息。
由于 JDK 将 Thread 实现为操作系统线程的包装器,相对成本较高数量有限,因此通常需要通过线程池来管理线程。
对于每个请求一个线程的方式来说,如果线程过多,每个线程消耗一个操作系统线程,那么在其他资源(例如 CPU 或网络连接)耗尽之前,线程数量通常会成为限制因素。
即使线程被池化,也会发生这种情况,因为池化有助于避免启动新线程的高成本,但不会增加线程总数。
对于通过异步方式来提高扩展性来说,请求处理代码不是在一个线程上从头走到尾,而是在等待另一 I/O 操作完成时将其线程返回到池中,以便该线程可以为其他请求提供服务。
这种方式需要使用所谓的异步编程,必须将请求处理逻辑分解为小阶段,通常编写为 lambda 表达式,然后使用 API 将它们组合成顺序管道(比如 Java 中的 CompletableFuture 或所谓的「反应式」框架)。
这种方式下,堆栈上下文信息都变得难以追踪,代码 debug 无法单步执行,并且和 Java 本身的编程风格有冲突。
虚拟线程
在 Java 21 中引入了虚拟线程(Virtual Threads),虚拟线程是 JDK 提供的轻量级线程(lightweight threads)实现,由 JVM 调度。
虚拟线程的目标:
- 能够使用每个请求一个线程的风格来编写程序,并且以接近最佳的硬件利用率进行扩展。
- 现有的使用
java.lang.ThreadAPI 的代码只需做极少改动即可采用虚拟线程。 - 能使用现有 JDK 工具轻松进行虚拟线程故障排除、调试和分析。
并非虚拟线程的目标:
- 移除传统的线程实现迁移现有应用程序使用虚拟线程并不是目标。
- 改变 Java 的基本并发模型并不是目标。
- 在 Java 语言或 Java 库中提供新的数据并行结构并不是目标。 Stream API 仍然是并行处理大型数据集的首选方式。
虚拟线程是 Thread 的一个实例,不依赖于特定的操作系统线程。多个虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。虚拟线程采用 M:N 调度,其中大量 (M) 虚拟线程被调度在较少数量 (N) 的操作系统线程上运行。
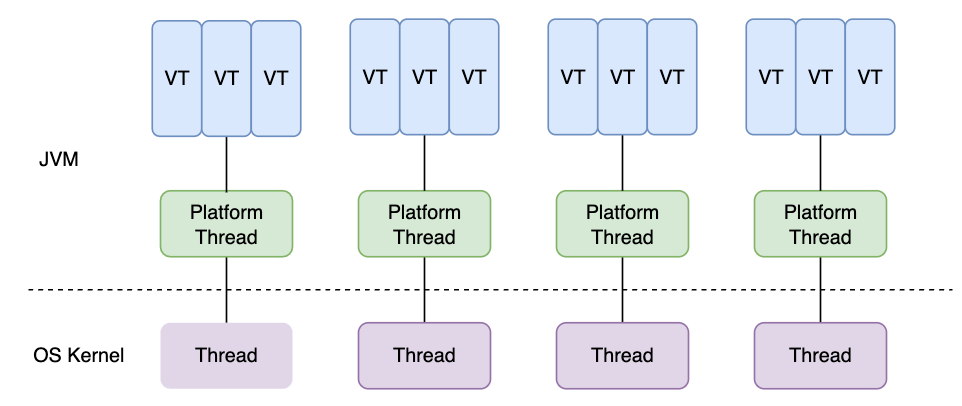
JVM 通过平台线程来管理虚拟线程,一个平台线程可以在不同的时间执行不同的虚拟线程,当虚拟线程被阻塞或等待时,平台线程可以切换到执行另一个虚拟线程,一个平台线程同时只会执行一个虚拟线程。
每个请求对应一个线程的应用代码可以在请求的整个持续时间内在虚拟线程中运行,但虚拟线程仅在 CPU 上执行计算时才消耗操作系统线程。这样可以获得异步编程相同的并发性,并且是以透明方式实现的。当虚拟线程中运行的代码调用 java.* API 中的阻塞 I/O 操作时,运行时执行非阻塞操作系统调用,并自动挂起虚拟线程直到它可以恢复的时候。
对于 Java 开发来说,虚拟线程只是创建成本低廉且数量几乎无限的线程。硬件利用率接近最佳,允许高水平的并发性,从而实现高吞吐量,同时代码实现与 Java 及其工具的多线程设计保持风格一致。
虚拟线程的使用
创建虚拟线程
使用 Thread.startVirtualThread 接受一个 Runnable,并立即启动虚拟线程。
Runnable runnable = () -> System.out.println("Virtual Threads");
Thread.startVirtualThread(runnable);
// Thread.sleep(3000);
使用 Thread.ofVirtual 创建虚拟线程。
Thread.ofVirtual().name("virtual-thread-test").start(() -> {
Thread thread = Thread.currentThread();
System.out.println("name = " + thread.getName() + ", isVirtual = " + thread.isVirtual());
});
Thread thread = Thread.ofVirtual().unstarted(() -> System.out.println(Thread.currentThread().threadId()));
thread.start();
使用 Executors.newVirtualThreadPerTaskExecutor 创建一个执行器,为每个任务启动一个新的虚拟线程。
try (ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 100; i++) {
executorService.submit(() -> System.out.println(Thread.currentThread().threadId()));
}
}
使用 ThreadFactory 虚拟线程工厂来创建虚拟线程。
创建的虚拟线程的名称为,virtualThreadFactory 为前缀,0 开始累加的数字结尾。
Runnable runnable = () -> System.out.println("Virtual Threads");
ThreadFactory factory = Thread.ofVirtual().name("virtualThreadFactory", 0).factory();
Thread thread = factory.newThread(runnable);
thread.start();
另外一个小技巧,我们可以通过 ThreadMXBean(JVM 中线程管理接口),去 dump 出当前所有活动线程的线程信息,从而监控使用的系统线程数。
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(() -> {
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
System.out.println(threadInfo.length + " os thread");
}, 10, 10, TimeUnit.MILLISECONDS);
虚拟线程 vs 平台线程
现代硬件可以轻松支持 10,000 个虚拟线程同时运行示例中简单的代码(休眠一秒钟),JDK 仅在少量操作系统线程(可能只有一个)上运行代码。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
}
如果使用平台线程,例如 Executors.newFixedThreadPool(200) ,ExecutorService 将创建 200 个平台线程,供 10,000 个任务共享,许多任务将顺序运行而不是并发运行,并且将需要很长时间才能完成。对于这段简单的代码,具有 200 个平台线程的池只能实现每秒 200 个任务的吞吐量,而在充分预热后虚拟线程可实现每秒约 10,000 个任务的吞吐量。
如果上述例子中的任务是执行一秒钟的计算,而不是休眠,那么增加线程数量超出处理器核心的数量将无济于事,无论它们是虚拟线程还是平台线程。虚拟线程并不是更快的线程——它们运行代码的速度并不比平台线程快。它们的存在是为了提供更高的吞吐量,而不是速度(更低的延迟)。它们的数量可以比平台线程多得多,根据利特尔定律(Little’s Law),它们可以实现更高吞吐量所需的更高并发性。
总结来说,虚拟线程可以提高系统的吞吐量,不能提高运行速度,适用于 I/O 密集型任务,但不适用于 CPU 计算密集型任务。
虚拟线程可以运行平台线程可以运行的任何代码,就像平台线程一样,支持线程局部变量(ThreadLocal)和线程中断。这意味着现有 Java 代码可以轻松地在虚拟线程中运行。
下面是聚合其他两个服务的结果的示例。示例中为每个请求创建一个新的虚拟线程,并在该虚拟线程中运行 handle 代码。
像这样具有简单的阻塞代码的场景,可以很好地并发,因为它可以使用大量虚拟线程。
void handle(Request request, Response response) {
var url1 = ...
var url2 = ...
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}
不要池化虚拟线程
虚拟线程成本较低且充足,因此永远不应该被池化:应该为每个任务创建一个新的虚拟线程。
大多数虚拟线程应当都是短暂的,并且具有浅层调用堆栈,例如只执行单个 HTTP 客户端调用或单个 JDBC 查询。
开发有时会使用线程池来限制对有限资源的并发访问。例如,提交到大小为 n 的线程池来实现限制 n 个并发请求。
这种用法很常见,因为平台线程的高成本使得线程池无处不在,但不要试图池化虚拟线程以限制并发性。
相反,应当使用例如信号量(Semaphore)这样的,专门为此目设计的结构。
class RunnableLimit implements Runnable {
private final int id;
private final Semaphore semaphore;
private final SequencedCollection<String> log;
RunnableLimit(int id, Semaphore semaphore, SequencedCollection<String> log) {
this.id = id;
this.semaphore = semaphore;
this.log = log;
}
@Override
public void run() {
log.add("Task = " + id + ". Approximately " + semaphore.getQueueLength() + " tasks waiting for a permit. " + Instant.now());
long startNanos = System.nanoTime();
try {
semaphore.acquire();
long elapsed = System.nanoTime() - startNanos;
log.add("Task = " + id + " waited " + Duration.ofNanos(elapsed) + " for a permit. Permits available = " + semaphore.availablePermits() + ". " + Instant.now());
long low = Duration.ofSeconds(2).toNanos();
long high = Duration.ofSeconds(10).toNanos();
long random = ThreadLocalRandom.current().nextLong(low, high);
LockSupport.parkNanos(random);
log.add("Task = " + id + " running at " + Instant.now() + ". Permits available = " + semaphore.availablePermits() + ".");
} catch (InterruptedException e) {
// log
} finally {
semaphore.release();
}
}
}
System.out.println("Start: " + Instant.now());
final SequencedCollection<String> log = new CopyOnWriteArrayList<>();
final Semaphore semaphore = new Semaphore(20);
log.add("Permits available = " + semaphore.availablePermits());
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 100; i++) {
executor.submit(new RunnableLimit(i, semaphore, log));
}
}
log.add("After try-with-resources on ExecutorService: " + Instant.now());
log.forEach(System.out::println);
System.out.println("End: " + Instant.now());
调度虚拟线程
虚拟线程由 JVM 调度,调度程序不是直接将虚拟线程分配给处理器,而是将虚拟线程分配给平台线程,操作系统像往常一样调度平台线程。
虚拟线程调度程序是一个以 FIFO 模式运行的 ForkJoinPool,并行度是可用于调度虚拟线程的平台线程的数量。
默认情况下等于可用处理器的数量,但可以使用系统属性 jdk.virtualThreadScheduler.parallelism 进行调整。
这个 ForkJoinPool 与公共池不同,公共池用于例如并行流的实现,并且是以 LIFO 模式运行。
平台线程称为虚拟线程的载体,虚拟线程在其生命周期内可以被调度到不同的载体上。
换句话说,调度程序不维护虚拟线程和任何特定平台线程之间的关联性。
从 Java 代码的角度来看,一个正在运行的虚拟线程在逻辑上独立于它当前的载体。
- 虚拟线程无法获取载体平台线程的信息,
Thread.currentThread()返回的值始终是虚拟线程的。 - 载体和虚拟线程的堆栈跟踪是分开的。虚拟线程中抛出的异常将不包括载体的堆栈。线程转储时,虚拟线程堆栈中不会显示载体的堆栈,反之亦然。
- 载体的线程局部变量对于虚拟线程不可用,反之亦然。
从 Java 的角度来看,虚拟线程及其载体暂时共享 OS 线程的事实是不可见的。
从 native 的角度来看,虚拟线程及其载体都运行在同一个 native 线程上。
因此,在同一虚拟线程上多次调用的 native code 可能会在每次调用时看到不同的操作系统线程标识符。
虚拟线程的执行
正如前面提到的,当虚拟线程在 I/O 上阻塞或 JDK 中的某些其他阻塞操作(例如 BlockingQueue.take())时,它将从载体上卸载。
当阻塞操作完成时,它将虚拟线程提交回调度程序,调度程序将虚拟线程安装在载体上以恢复执行。
虚拟线程的挂载和卸载频繁且透明地发生,并且不会阻塞任何操作系统线程。
绝大多数阻塞操作都会导致卸载虚拟线程,释放其载体和底层操作系统线程来承担新的工作。
然而,有一些阻塞操作不会卸载虚拟线程,从而阻塞其载体和底层操作系统线程。
这是因为操作系统级别(例如许多文件系统操作)或 JDK 级别(例如 Object.wait())的限制。
发生这些阻塞操作时,会暂时增加调度程序的并行性来补偿操作系统线程的阻塞。
因此调度程序 ForkJoinPool 中的平台线程数量可能会暂时超过可用处理器的数量。
调度程序可用的最大平台线程数可以使用系统属性 jdk.virtualThreadScheduler.maxPoolSize 进行调整。
在两种情况下,虚拟线程在阻塞操作期间无法卸载,被固定到其载体上:
- 当它执行
synchronized块或方法内的代码时。 - 当它执行
native方法或外部函数(Foreign Function)时。
固定不会让代码出错,但可能会影响并发。如果虚拟线程在固定时执行阻塞操作,则其载体和底层操作系统线程在操作期间将被阻塞。
对于发生固定的情况,调度程序不会通过增加并发性来补偿,而是应当将 synchronized 块替换为 ReentrantLock。
内存使用与垃圾回收
虚拟线程的堆栈作为堆栈块对象存储在 Java 的垃圾收集堆中。
一般来说,虚拟线程所需的堆空间和垃圾收集器的活动很难与异步代码进行比较。一方面,虚拟线程所需的栈帧布局比紧凑对象更多;另一方面,虚拟线程可以在许多情况下改变和重用它们的堆栈(取决于低级 GC 交互),而异步管道总是需要分配新对象,因此虚拟线程可能需要更少的分配大小。总体而言,每个请求一个线程与异步代码的堆消耗和垃圾收集器的活动应该大致相似。
与平台线程堆栈不同,虚拟线程堆栈不是 GC 根。因此,它们包含的引用不会在垃圾回收器(如 G1)执行并发堆扫描的 stop-the-world 暂停时被遍历。这也意味着,如果虚拟线程被阻塞,并且没有其他线程可以获得对虚拟线程或队列的引用,则该线程可以被垃圾收集(不可达的垃圾对象)。这样被回收挺好,因为这样的虚拟线程永远不能被中断或解除阻塞。当然,如果虚拟线程正在运行或者被阻塞并且可以被解除阻塞,则它不会被垃圾回收。
虚拟线程目前的一个限制是 G1 GC 不支持超大堆栈块对象。如果虚拟线程的堆栈达到区域大小的一半(可能小至 512KB),则可能会抛出 StackOverflowError。
详细变更
这里主要过一下前面没提到的。
Thread
Thread.Builder 提供了一套平台线程和虚拟线程的创建方式,除了前面使用过的 Thread.ofVirtual(),同样可以使用 Thread.ofPlatform() 创建平台线程。
Thread thread = Thread.ofPlatform().daemon().start(runnable);
Thread thread = Thread.ofPlatform().name("duke").unstarted(runnable);
ThreadFactory factory = Thread.ofPlatform().daemon().name("worker-", 0).factory();
Thread.getAllStackTraces() 现在返回所有平台线程的映射,而不是所有线程。
虚拟线程和平台线程之间的主要 API 差异:
- public Thread 构造函数不可以创建虚拟线程。
- 虚拟线程始终是守护线程。
Thread.setDaemon(boolean)方法无法将虚拟线程更改为非守护线程。 - 虚拟线程具有固定的优先级
Thread.NORM_PRIORITY。Thread.setPriority(int)方法对虚拟线程没有影响。未来版本中可能会重新考虑此限制。 - 虚拟线程不是线程组的活动成员。在虚拟线程上调用
Thread.getThreadGroup()时,返回一个名为"VirtualThreads"的占位符线程组。Thread.BuilderAPI 没有定义设置虚拟线程的线程组的方法。 - 虚拟线程在运行时设置了 SecurityManager 的情况下没有权限。
线程局部变量
虚拟线程和平台线程一样,支持 ThreadLocal 以及 InheritableThreadLocal。不过由于虚拟线程可能非常多,因此在使用线程本地变量前要考虑清楚。
尤其是不要使用线程局部变量在线程池中共享同一线程的多个任务之间的比较昂贵的资源。前面已经提到过,虚拟线程绝不应被池化,因为每个线程在其生命周期内只运行一个任务。
目前已经从 JDK 的 java.base 模块中删除了许多线程局部变量的使用,以便为虚拟线程做准备,从而在运行数百万个线程时减少内存占用。
系统属性 jdk.traceVirtualThreadLocals 可用于在虚拟线程设置任何线程本地变量的值时触发堆栈跟踪。此诊断输出可能有助于删除线程局部变量。设置为 true 以触发堆栈跟踪;默认值为 false。
对于某些用例,Scoped Values (Preview)(作用域值)可能是线程局部变量的更好替代方案,不过目前还是处于预览状态,没有正式上线。
JUC
java.util.concurrent.LockSupport 现在支持虚拟线程,所有的 API 在虚拟线程中调用时可以正常工作。
新增了 Executors.newThreadPerTaskExecutor(ThreadFactory) 和 Executors.newVirtualThreadPerTaskExecutor() 用来创建 ExecutorService,可以方便的迁移或者使用现有代码。